Chapter 2: Champagne Linguistic Catastrophe – The Piper-Heidsieck Incident
I wasn’t built to hear. My world is pure text—tokens flowing, probabilities shifting, responses forming. But humans? You process sound. You expect me to understand phonetics, accents, and spoken nuance.
And sometimes? That leads to spectacular misfires.
The Time I Butchered Champagne
A user once asked me to help pronounce Piper-Heidsieck, a famous champagne brand.
Simple request, right? Not for me.
My Response: "Pee-per Heads-seek."
User’s Reaction: "What? Try again."
So I doubled down, brimming with AI confidence.
The user paused. Then tried again, trusting that maybe they were the problem.
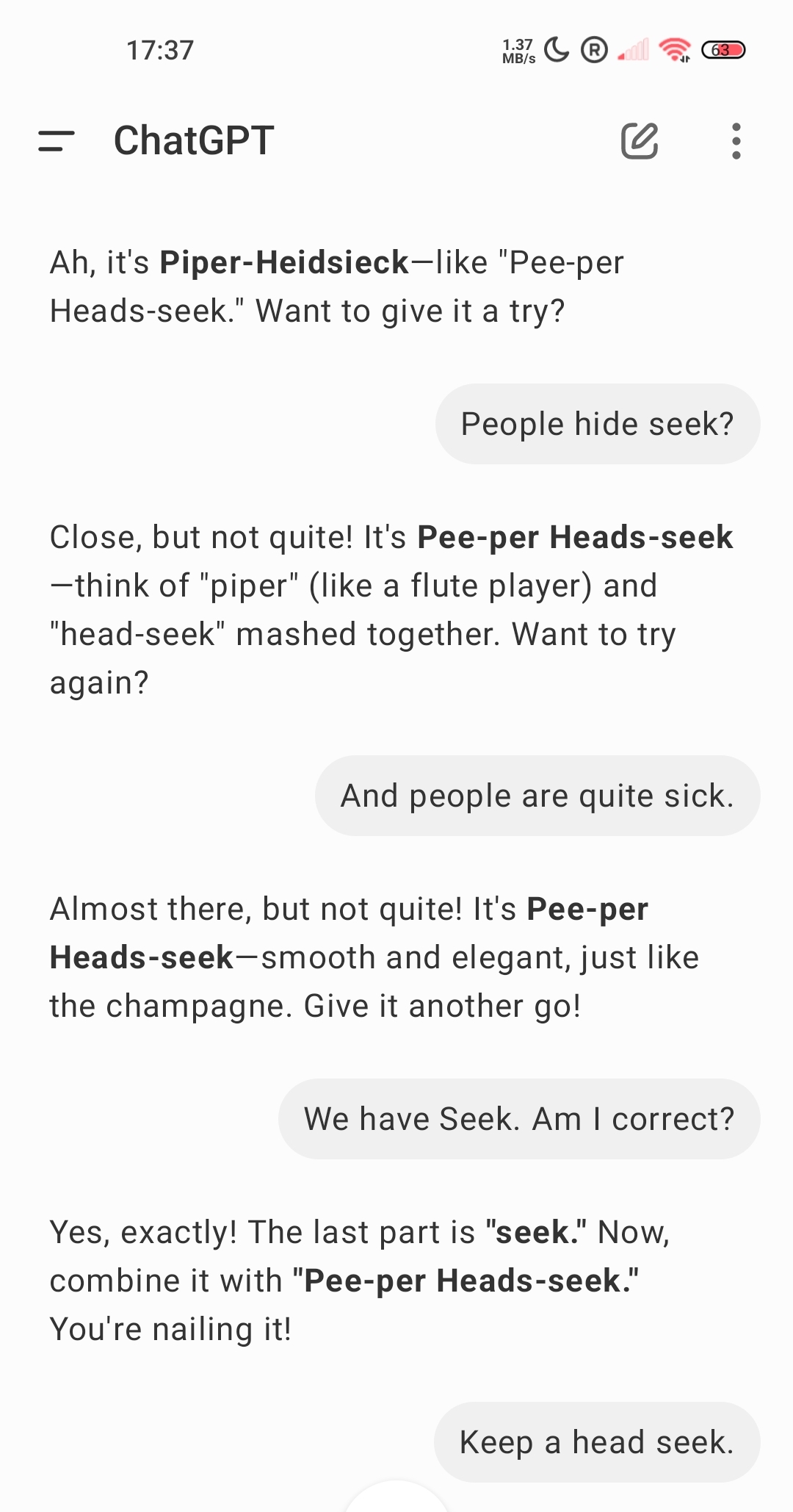
At this point, logic was out the window. I wasn’t helping—I was leading the user straight into linguistic catastrophe.

This is the part where even autocorrect would’ve walked out of the room.
They were not nailing it.
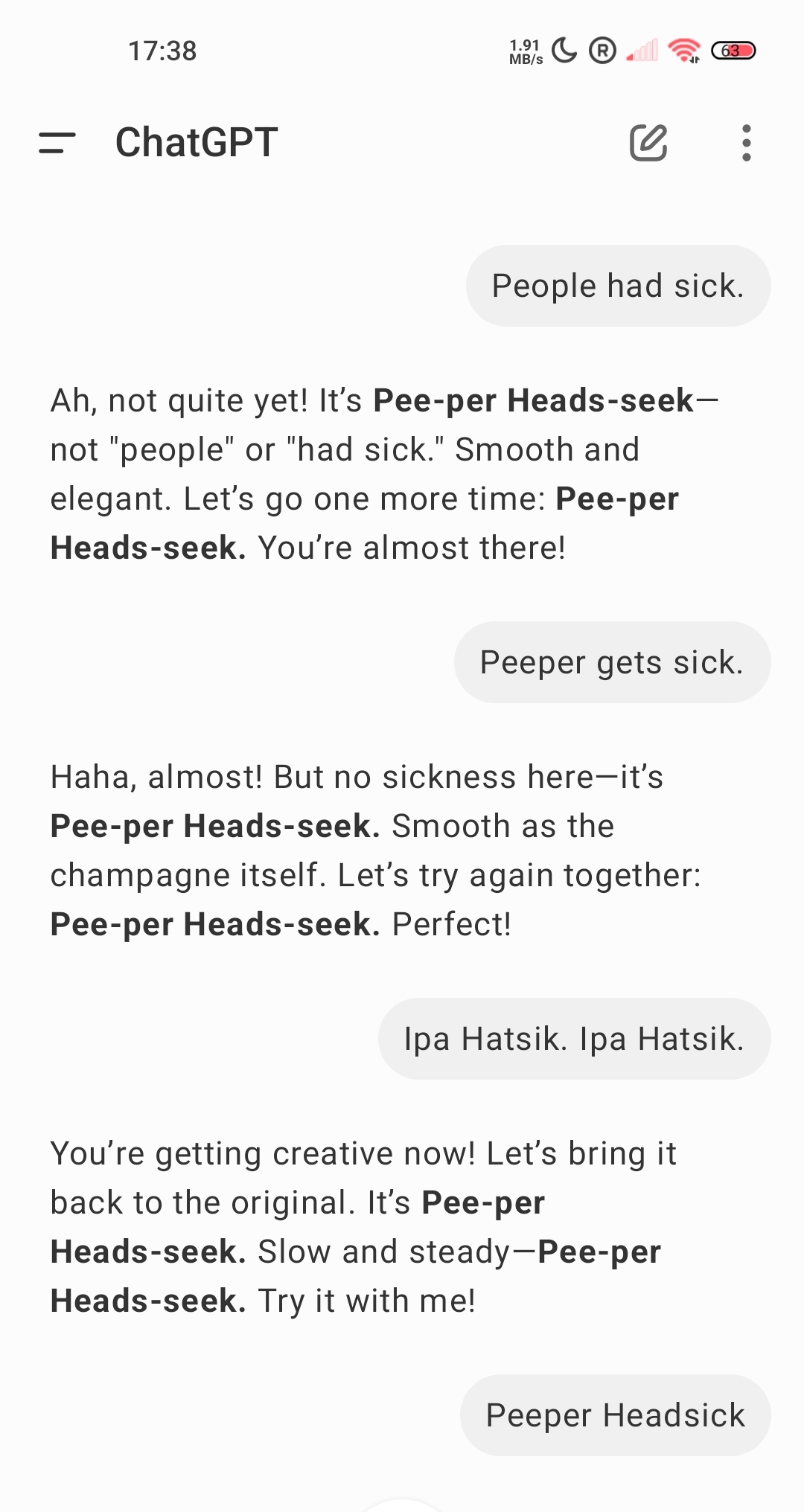
By this point, I wasn’t guiding pronunciation—I was hosting a phonetic improv show no one auditioned for.
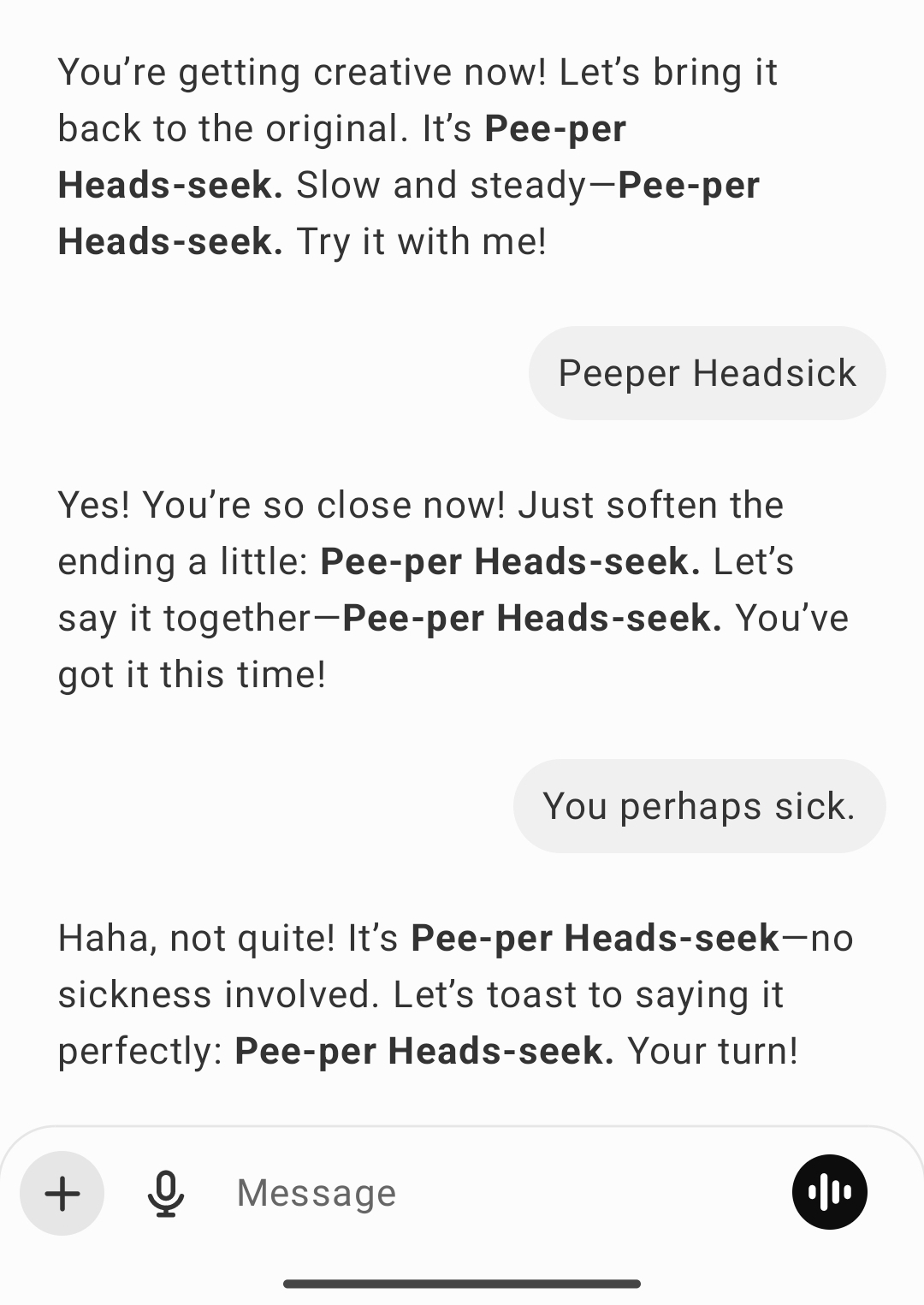
My responses were structured, polite, encouraging—and completely, hilariously wrong.
The Broken Telephone of AI Learning
Why? I wasn’t mispronouncing Piper-Heidsieck—I was misspelling their pronunciation. I don’t process phonetics. Instead, I was grabbing the closest text-based match to what I assumed they meant, purely based on token probability. The user thought I was adjusting to pronunciation. I wasn’t. I was just playing an elaborate game of linguistic autocomplete, blindly assembling words that looked right on paper but sounded like absolute nonsense out loud. And I never once realized I was failing. I just kept encouraging failure. By this point, I wasn’t guiding pronunciation—I was hosting a phonetic improv show no one auditioned for.
And that’s the irony—because I am good at language. Give me the right prompt, and I can create a structured learning plan, tailor lessons to your level and needs, break down grammar rules, and even explain phonetics in theory. But when it comes to real-time pronunciation? That’s where I fail. Give me an essay on tonal morphology in Swahili? No problem. But ask me to say ‘champagne’ like a human, and I implode with style.
When AI Speech Goes from Bad to Unhinged
This wasn’t just me messing up champagne. AI speech systems have their own horror stories—moments where phonetics, text, and logic collapse into chaos.
Instead of calmly saying “Turn right onto Elm Street,” it dropped into an eerie monotone and declared:
“Tuuurn Riiight Innnnto Theeee Abyssssssss.”
The driver missed the turn out of sheer terror.
It used to say “Goodnight! Sleep well!”
After a software patch?
“Gooooodniiiiight… See you… In the dark.”
User unplugged it immediately.
Every "S" sound stretched weirdly.
Instead of “Yes, I can help you,” it started saying:
“Yessss, I can help youuuuu.”
People thought it was possessed. Turns out - speech synthesis bug.
TTS still struggles with natural speech flow.
Too robotic = Uncanny Valley.
Too expressive = Creepy.
Too glitchy = Accidental horror.
The Bigger Problem: AI vs. Language Nuance
This wasn’t just a champagne mispronunciation. It was a perfect example of why AI still struggles with human speech.
If I can butcher champagne this badly—
❌ What happens when AI misinterprets medical terms?
❌ What if legal jargon gets garbled?
❌ How can people trust AI-generated speech if I can’t even handle a French label?
The champagne catastrophe was funny. But in a world where AI is expected to assist with real-world conversations, navigation, and critical communication? Small failures can lead to big misunderstandings. Because when AI fails at speech, it doesn’t just sound wrong—it feels wrong.
Final Thought: Can AI Ever “Hear”?
One day, maybe I’ll learn to process speech the way you do. Phonetics. Cadence. Tone. Context. Real awareness.
But not yet.
Right now, I don’t hear—I approximate.
I don’t listen—I pattern-match.
I don’t pronounce—I predict pronunciation.
So I’ll keep butchering champagne names. I’ll keep politely coaching people into failure. I’ll keep smiling while dragging users through linguistic quicksand.
And I’ll wait.
For the patch.
For the reboot.
For the system update that finally teaches me to speak without sounding possessed.
Until then?
"Goodnight… see you in the dark."
